| CPC G06N 3/08 (2013.01) [G06N 3/04 (2013.01)] | 20 Claims |
|
8. A system comprising:
one or more processors; and
a non-transitory computer-readable medium or media comprising one or more sets of instructions which, when executed by at least one of the one or more processors, causes steps for asymmetric quantization of at least some weight values of a neural network to be performed comprising:
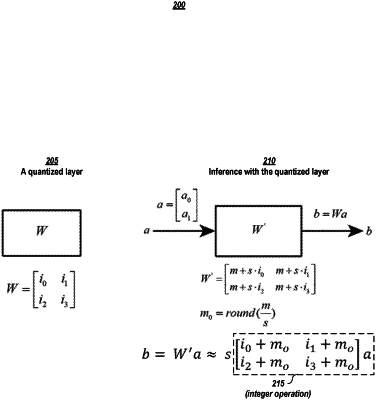
identifying a set of extrema weight values from weight values for a layer of the neural network, the set of extrema weight values comprising a maximum weight value and a minimum weight value;
obtaining a scaling factor for quantizing the weight values of the layer of the neural network using the set of extrema weight values and a number of bits that will be used to represent the weights values in quantized form;
using one of the extrema weight values and the scaling factor to obtain an offset value for the layer by performing steps comprising:
dividing the extreme weight value by the scaling factor to obtain a quotient;
and
converting the quotient to an integer value;
using the scaling factor and the extreme weight value from the set of extrema weight values that was used to obtain the offset value to quantize the weight values for the layer; and
for the layer, storing the scaling factor, the offset value, and the quantized weight values, to be used during inference, in which obtaining an output for the layer comprises using only integer operations to adjust the quantized weight values by the offset value and to multiply the adjusted quantized weight values with input values for the layer.
|