| CPC G06F 9/30036 (2013.01) [G06F 9/3001 (2013.01); G06F 9/30014 (2013.01); G06F 9/3016 (2013.01); G06F 9/3802 (2013.01)] | 21 Claims |
|
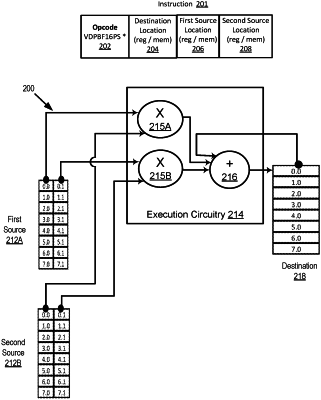
1. A processor comprising:
fetch circuitry to fetch a single instruction having fields to specify an opcode and locations of first source, second source, and destination vectors, the opcode to indicate execution circuitry is to multiply N pairs of elements of the specified first and second sources having a 16-bit floating-point format of a sign bit, an 8-bit exponent, and a mantissa comprising 7 explicit bits and an eighth implicit bit, and accumulate resulting products with previous contents of a corresponding element of the specified destination;
decode circuitry to decode the fetched instruction; and
the execution circuitry to respond to the decoded instruction as specified by the opcode.
|