| CPC G06F 40/58 (2020.01) [G06F 18/25 (2023.01); G06F 40/30 (2020.01); G06F 40/44 (2020.01); G06N 3/04 (2013.01); G06V 30/274 (2022.01)] | 20 Claims |
|
1. A method for providing multimodal translation of a content in a source language, the method comprising:
receiving a user input with respect to a translation request of text included in the content;
in response to receiving the user input, acquiring a multimodal input from the content, the multimodal input including location information related to the content and other multimodal inputs, the location information corresponding to a geographical location from where the content is derived;
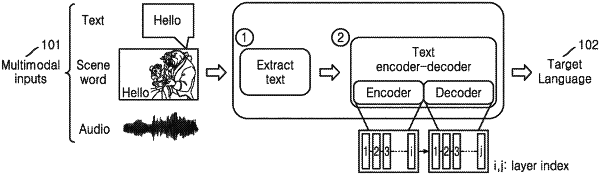
generating scene information representing the multimodal input related to the content by using a fusion layer configured to fuse location entity semantic information extracted based on the location information, and source text semantic information and a multimodal feature extracted based on the other multimodal inputs, into a fusion result such that the scene information is generated based on the fusion result;
identifying a candidate word set in a target language;
determining at least one candidate word from the candidate word set based on the scene information; and
translating the text included in the content into the target language using a translation model based on the determined at least one candidate word.
|