| CPC G06F 40/40 (2020.01) [G06N 3/04 (2013.01); G06V 30/19147 (2022.01)] | 20 Claims |
|
8. A system comprising:
a memory storage device for storing computer-executable instructions; and
at least one processor, which, when executing the computer-executable instructions, causes the system to:
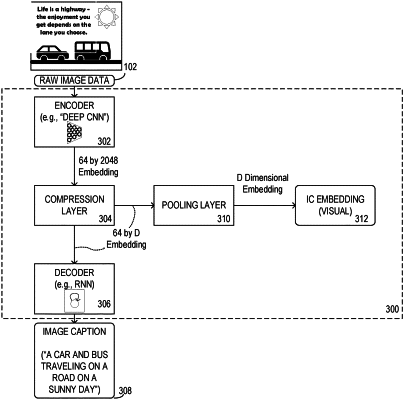
with a machine learning algorithm, train an encoder-decoder model to generate a caption for an image by generating with the encoder an embedding, and then decoding the embedding with the decoder to generate the caption, wherein a dataset comprising a plurality of images with associated captions is used to train the encoder-decoder model;
generate a first embedding for the image by:
detecting words present in an image with an optical character recognition (OCR) algorithm;
using pre-trained word embeddings to derive a word embedding for each word detected in the image; and
performing an average pooling operation on the word embeddings for each word detected in the image, wherein the result of the average pooling operation is the first embedding for the image;
generate a second embedding for the image by:
using the image as input to the pre-trained encoder-decoder model, generate from the image with the encoder the second embedding for the image;
concatenate the first embedding with the second embedding to derive for the image a final embedding; and
store the final embedding for the image.
|