| CPC H04N 19/107 (2014.11) [H04N 19/122 (2014.11); H04N 19/176 (2014.11); H04N 19/50 (2014.11)] | 20 Claims |
|
1. A method for decoding video data from a video bitstream, the method comprising:
for a respective block of a plurality of blocks encoded into the video bitstream using a prediction mode:
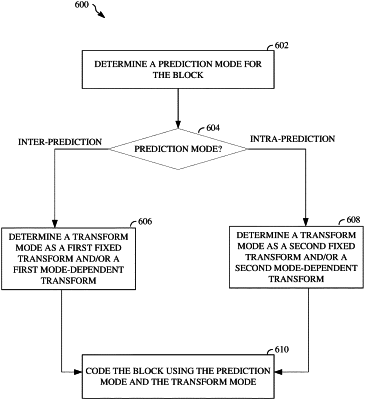
determining a transform mode for the block using the prediction mode, wherein:
the transform mode comprises a first transform mode responsive to the prediction mode being an inter-prediction mode,
the transform mode comprises a second transform mode responsive to the prediction mode being an intra-prediction mode of a plurality of available intra-prediction modes,
the first transform mode comprises one of a plurality of available first transform types, each of the plurality of available first transform types comprising respective combinations of transforms selected from the group consisting of:
first fixed transforms, each comprising a respective fixed transformation matrix, and
first mode-dependent, learned transforms, each comprising a respective transformation matrix that was generated iteratively using blocks predicted using the inter-prediction mode,
the second transform mode comprises one of a plurality of available second transform types, each of the plurality of available second transform types comprising respective combinations of transforms selected from the group consisting of:
second fixed transforms, each comprising a respective fixed transformation matrix, wherein the second fixed transforms comprise a proper subset of the first fixed transforms, and
a second mode-dependent, learned transform comprising a transformation matrix that is generated iteratively using blocks predicted using the intra-prediction mode; and
decoding the block using the prediction mode and the transform mode.
|