| CPC G10L 25/30 (2013.01) [G10L 15/02 (2013.01); G10L 15/10 (2013.01); G10L 25/48 (2013.01)] | 9 Claims |
|
1. A tag estimation device comprising:
a hardware processor that:
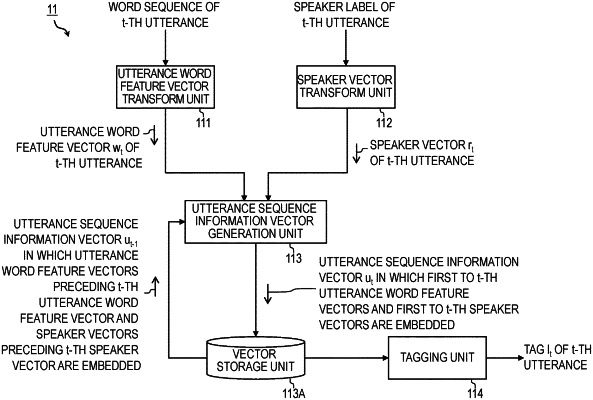
retrieves a t-th utterance of a sequence of utterances in a dialogue from memory, wherein the sequence of utterances was stored in the memory following receipt of the sequence of utterances from a microphone or from a transmission of data over a communication line, wherein the t-th utterance is spoken by a speaker of a plurality of speakers in the dialogue, the t-th utterance includes a word, and the t is a natural number;
generates, based on the t-th utterance, a t-th speaker vector and a t-th utterance word feature vector;
retrieves from the memory a (t−1)-th utterance sequence information vector ut-1 that includes an utterance word feature vector that precedes the t-th utterance word feature vector and a speaker vector that precedes the t-th speaker vector,
generates, by a recurrent neural network (RNN), based on the t-th utterance word feature vector, the t-th speaker vector, and the (t−1)-th utterance sequence information vector ut-1, a t-th utterance sequence information vector ut,
wherein the t-th utterance sequence information vector ut, is based on recursively combining pieces of a series of respective uttered word feature vectors and speaker vectors from a first utterance to the t-th utterance of the sequence of utterances in the dialogue, each speaker vector of an utterance in the sequence of utterances represents a speaker of the plurality of speakers speaking the utterance,
wherein the t-th utterance word feature vector is associated with at least the word in the t-th utterance spoken by the speaker, the t-th speaker vector is associated with the speaker, and the t-th utterance sequence information vector ut represents a feature associated with the t-th utterance in a sequence of utterances in a dialogue, the generating the t-th utterance sequence information vector ut further comprises operating according to the formula:
ct=[wtT,rtT]T, and
ut=RNN(ct, ut-1), the RNN represents a function having capabilities of a recurrent neural network, the T represents a transposition of a vector, the wt represents an utterance word feature vector of the t-th utterance, and the rt represents a speaker vector of the t-th utterance;
determines a tag lt associated with the t-th utterance, wherein the tag lt represents a result of analyzing the t-th utterance from a predetermined model parameter and the t-th utterance sequence information vector ut, wherein the tag lt specifies a scene in the dialogue;
storing in the memory the t-th speaker vector, the t-th utterance word feature vector, and the i-th utterance sequence information vector ut for performing tag estimation of a subsequent utterance; and
transmitting the tag lt associated with the t-th utterance to program instructions configured to output the tag lt.
|