| CPC G10L 15/08 (2013.01) [G10L 15/005 (2013.01); G10L 15/02 (2013.01); G10L 2015/088 (2013.01)] | 20 Claims |
|
1. A computer-implemented method for automatic speech recognition (ASR) processing, the computer-implemented method comprising:
receiving audio data corresponding to a spoken input;
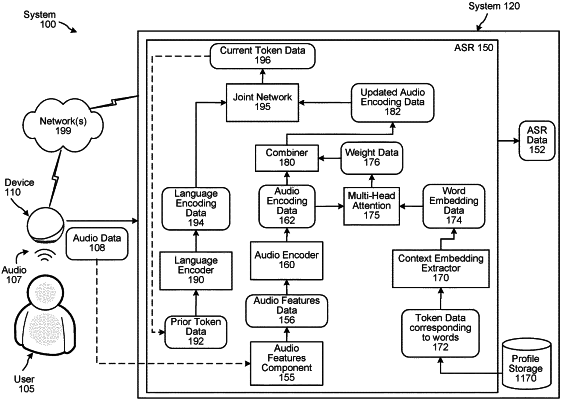
determining, using the audio data, a plurality of audio frames including an audio frame, the audio frame comprising a portion of the audio data;
determining, using a first set of audio frames of the plurality of audio frames, first audio feature data corresponding to a frequency domain representation of the first set of audio frames;
processing, using an audio encoder, the first audio feature data to determine first audio encoding data corresponding to a latent representation of features corresponding to the first set of audio frames;
determining user profile data corresponding to the spoken input;
determining, using a portion of the user profile data, first word embedding data corresponding to a vector representation of the portion of the user profile data;
processing, using a first multi-head attention component, the first audio encoding data and the first word embedding data to determine first weight data, the first multi-head attention component configured to determine a similarity between audio features and word embeddings, the first weight data being based on at least the portion of the user profile data being represented in the first audio encoding data;
determining, using the first audio encoding data and the first weight data, updated first audio encoding data;
determining first language encoding data using a language encoder and first language data, the first language data corresponding to at least a second set of audio frames, of the plurality of audio frames, occurring prior to the first set of audio frames, the first language data including at least a first token corresponding to at least a first subword represented in the second set of audio frames; and
processing, using a joint network, the updated first audio encoding data and the first language encoding data to determine second language data including a second token corresponding to a second subword represented in the first set of audio frames.
|