| CPC G06V 40/45 (2022.01) [G06F 18/253 (2023.01); G06N 20/00 (2019.01); G06V 40/172 (2022.01); G06V 40/70 (2022.01); G10L 17/06 (2013.01); G06V 40/178 (2022.01)] | 16 Claims |
|
1. A computer implemented method of applying machine learning to authenticate a customer's identity via live video, comprising:
building convolutional neural network (“CNN”) models for at least two of a sentiment module, a face identity document match (“face ID match”), a liveness module, a voice module, and a politically exposed person (“PEP”) module on at least two different computation nodes by:
receiving, at a model building planner, module data;
creating, by the model building planner, dispatchable transaction packages at a module data building pool;
sharing the dispatchable transaction packages with the at least two computation nodes; and
dynamically coordinating, by a model building scheduler, training progress among the at least two computation nodes;
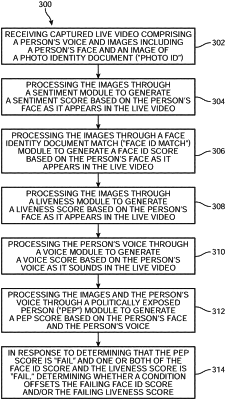
receiving captured live video comprising a person's voice and images including a person's face and an image of a photo identity document (“photo ID”);
processing the images through the sentiment module to generate a sentiment score based on the person's face as it appears in the live video;
processing the images through the face ID match module to generate a face ID score based on the person's face as it appears in the live video;
processing the images through the liveness module to generate a liveness score based on the person's face as it appears in the live video;
processing the person's voice through the voice module to generate a voice score based on the person's voice as it sounds in the live video;
processing the images and the person's voice through the PEP module to generate a PEP score based on the person's face and the person's voice; and
in response to determining that one or both of the face ID score and the liveness score is “fail,” determining whether a condition offsets the failing face ID score and/or the failing liveness score;
processing the images through a machine learning model to determine, based on the photo ID, whether the person's age is above a predetermined threshold, wherein the person's age is determined to be above the predetermined threshold and the person's age is the condition; and
in response to determining that PEP score is “pass,” disallowing an offset based on whether a condition offsets the score of “fail.”
|