| CPC G06V 40/23 (2022.01) [G01S 7/4808 (2013.01); G01S 17/89 (2013.01); G06T 7/251 (2017.01); G06T 7/596 (2017.01); G06T 2200/08 (2013.01); G06T 2207/10021 (2013.01); G06T 2207/30196 (2013.01)] | 16 Claims |
|
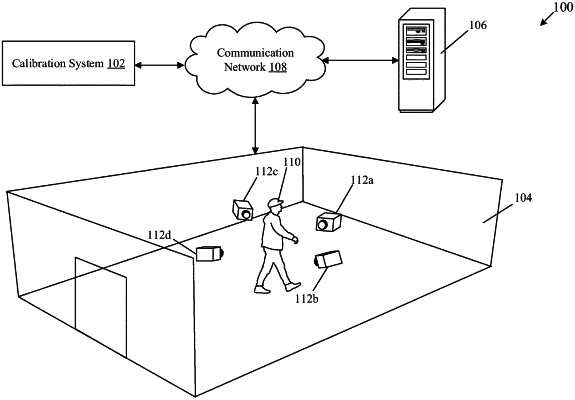
1. A calibration system, comprising:
circuitry configured to:
receive a set of depth scans and a corresponding set of color images of a scene comprising a human-object as part of a foreground of the scene;
extract a first three-dimensional (3D) representation of the foreground based on a first depth scan of the set of depth scans, wherein the first 3D representation is associated with a first viewpoint in a 3D environment;
spatially align the extracted first 3D representation with a second 3D representation of the foreground, wherein the second 3D representation is associated with a second viewpoint in the 3D environment;
update the spatially aligned first 3D representation based on the corresponding set of color images and a set of structural features of the human-object, as a human-prior;
extract a third 3D representation of a ground surface in the scene based on the first depth scan associated with the first viewpoint;
spatially align the extracted third 3D representation of the ground surface with a fourth 3D representation of the ground surface, the fourth 3D representation being associated with the second viewpoint of the scene;
update the spatially aligned first 3D representation further based on the spatial alignment of the extracted third 3D representation with the fourth 3D representation; and
reconstruct a 3D mesh of the human-object based on the updated first 3D representation of the foreground.
|