| CPC G06T 13/40 (2013.01) [G06T 7/73 (2017.01); G06V 10/24 (2022.01); G06V 10/774 (2022.01); G06V 10/82 (2022.01); G06V 40/161 (2022.01); G06V 40/171 (2022.01); G06V 40/174 (2022.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30201 (2013.01)] | 20 Claims |
|
1. A computer-implemented method, comprising:
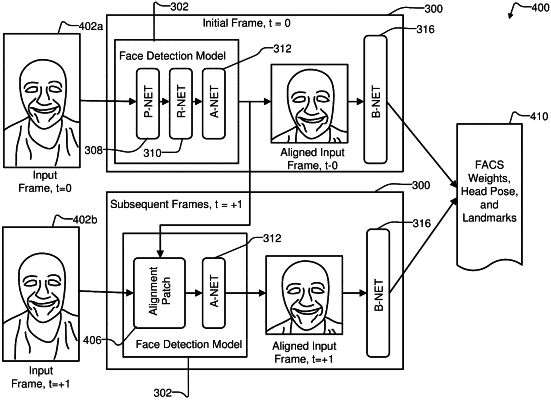
identifying, using a fully convolutional network, a set of bounding box candidates from a first frame of a video, wherein each bounding box candidate includes a face;
refining, using a convolutional neural network, the set of bounding box candidates into a bounding box;
obtaining a first set of one or more of a predefined facial expression weight, a head pose, and facial landmarks based on the bounding box and the first frame using an overloaded output convolutional neural network;
generating a first animation frame of an animation of a three-dimensional (3D) avatar based on the first set of the one or more of the predefined facial expression weight, the head pose, and the facial landmarks, wherein a head pose of the avatar matches the head pose in the first set and facial landmarks of the avatar match the facial landmarks in the first set; and
for each additional frame of the video subsequent to the first frame,
detecting whether the bounding box, applied to the additional frame, includes the face;
if it is detected that the bounding box includes the face, bypassing the fully convolutional network and the convolutional neural network, and obtaining an additional set of the one or more predefined facial expression weights, head poses, and facial landmarks based on the bounding box and the additional frame, by using the overloaded output convolutional neural network; and
generating an additional animation frame of the animation of the 3D avatar using the additional set.
|