| CPC G06T 13/205 (2013.01) [G06N 3/045 (2023.01); G06T 13/40 (2013.01); G10L 15/04 (2013.01); G10L 15/187 (2013.01); G10L 15/30 (2013.01)] | 19 Claims |
|
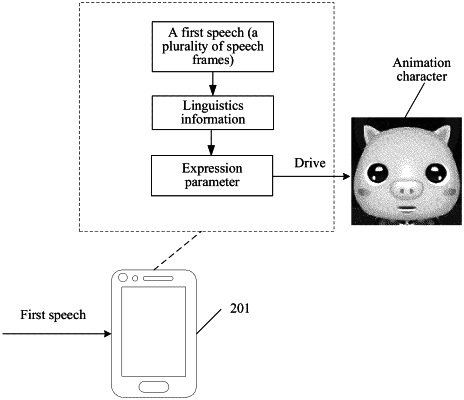
1. A speech-driven animation method, performed by an audio and video processing device, the method comprising:
obtaining a first speech with an acoustic feature, the first speech comprising a plurality of speech frames;
determining linguistics information corresponding to a speech frame in the first speech by applying a neural network mapping model to extract the acoustic feature, the linguistics information being used for identifying a distribution possibility that the speech frame in the first speech pertains to phonemes;
determining an expression parameter corresponding to the speech frame in the first speech according to the linguistics information, wherein the expression parameters do not reflect pronunciation habits of different speakers; and
enabling, according to the expression parameter, an animation character to make an expression corresponding to the first speech.
|