| CPC G06N 3/08 (2013.01) [G06F 16/353 (2019.01); G06F 18/22 (2023.01); G06F 40/247 (2020.01); G06N 3/04 (2013.01); G06V 30/18057 (2022.01); G06V 30/262 (2022.01); G06V 30/40 (2022.01)] | 18 Claims |
|
1. A system for automated contextual processing, the system comprising:
a processor;
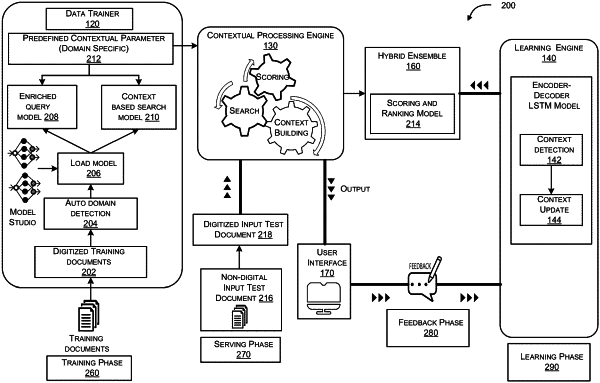
a data trainer coupled to the processor, the data trainer to:
classify, using a classification model, a plurality of extracted parameters from a set of digitized training documents, wherein the classification is performed to assign a document similarity score with respect to a set of reference documents corresponding to a plurality of domains;
detect automatically, a domain for the set of digitized training documents based on the document similarity score; and
load a domain based neural model for the detected domain to generate a plurality of pre-defined contextual parameters specific to the detected domain, the plurality of pre-defined contextual parameters being obtained by extraction of multiple queries from the set of digitized training documents and subsequent processing of the extracted queries;
a contextual processing engine of the processor, the engine to:
receive a set of input documents obtained by digitization of a non-digital documents;
perform, through an AI model, a contextual processing of the received set of input documents based on the pre-defined contextual parameters to obtain an output in form of a plurality of filtered snippets each bearing a corresponding rank, the contextual processing comprising context building, context search and context-based ranking of one or more snippets extracted from the input documents; and
wherein a context-based verification of the unstructured data is performed based on the plurality of filtered snippets and the corresponding rank; and
a hybrid ensemble coupled to the processor, wherein the hybrid ensemble is configured to:
receive, from the contextual processing engine, a first data comprising the plurality of filtered snippets;
receive, from a learning engine coupled to the processor, a second data comprising an updated plurality of filtered snippets;
classify, using one or more models, the first data and the second data in a pre-defined format;
assign, using the one or more models, a pre-defined weight to each of the classified first data and the classified second data;
determine, using the one or more models, a similarity score based on the assigned weights; and
update, using the one or more models, the rank of each snippet in the plurality of filtered snippets to assign an updated rank.
|