| CPC G06F 40/295 (2020.01) [G06F 18/214 (2023.01); G06F 40/247 (2020.01); G06F 40/284 (2020.01); G06F 40/35 (2020.01); G06N 3/08 (2013.01); G06N 20/00 (2019.01); H04L 51/02 (2013.01)] | 20 Claims |
|
1. A computer implemented method for generating a training dataset for machine learning based models for natural language processing, the method comprising:
receiving a set of natural language phrases;
generating a plurality of user responses from the set of natural language phrases, the generating comprising:
selecting a natural language phrase from the set of natural language phrases;
processing the selected natural language phrase to extract an entity of a particular named entity type;
generating a user response associated with the particular named entity type based on the extracted entity; and
determining whether to collect a plurality of context strings, each context string associated with a named entity type, wherein the determining is based on whether a length of a natural language phrase associated with the named entity type is shorter than a threshold length;
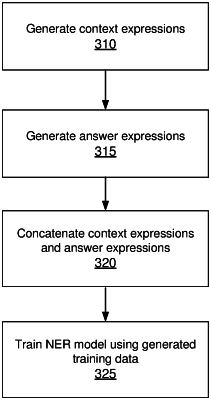
receiving, based on determining whether to collect the plurality of context strings, the plurality of context strings;
generating the training dataset by repeating for a named entity type:
selecting a context string associated with the named entity type from the plurality of context strings;
selecting a user response associated with the named entity type from the plurality of user responses, wherein the selecting is random in response to an amount of context strings in the plurality of context strings and an amount of user responses in the plurality of user responses being above a threshold amount, and wherein the selecting is according to a pattern such that each context string in the plurality of context strings is selected with each user response in the plurality of user responses in response to the amount of context strings in the plurality of context strings and the amount of user responses in the plurality of user responses being below a threshold amount; and
adding a pair of the selected context string and the selected user response to the training dataset; and
using the training dataset for training a machine learning based model for use in named entity recognition.
|