| CPC G06F 40/289 (2020.01) [G06F 16/2468 (2019.01); G06F 16/248 (2019.01); G06N 3/04 (2013.01)] | 15 Claims |
|
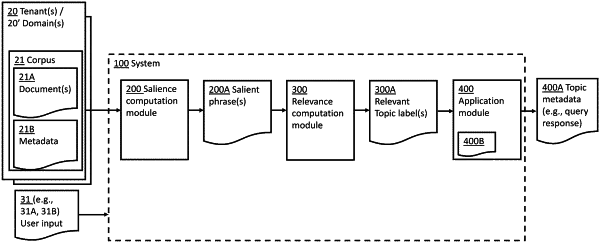
9. A system for automatic topic detection in text, the system comprising: a non-transitory memory device, wherein modules of instruction code are stored, and at least one processor associated with the memory device, and configured to execute the modules of instruction code, whereupon execution of said modules of instruction code, the at least one processor is configured to:
receive a first text document of a first plurality of text documents wherein the first plurality of documents pertains to a first business domain;
extract one or more phrases from the first text document, each phrase comprising one or more words, based on one or more syntactic patterns;
for each phrase:
apply a word embedding neural network (NN) on one or more words of the phrase, to obtain one or more respective word embedding vectors;
calculate a weighted phrase embedding vector, based on the one or more word embedding vectors; and
compute a phrase saliency score, based on the weighted phrase embedding vector;
produce one or more topic labels, representing one or more respective topics of the at least one first text document, based on the computed phrase saliency score of each phrase;
obtain a second plurality of documents pertaining to at least one second business domain;
for each topic label:
calculate a foreground probability value, representing probability of the topic label to represent a topic comprised in the first plurality of documents;
calculate a background probability value, representing probability of the topic label to represent a topic comprised in one of the first plurality of documents and the second plurality of documents; and
calculate a relevance score, representing pertinence of the topic label to the first business domain, based on the foreground probability value and the background probability value.
|