| CPC G06F 40/242 (2020.01) [G06F 40/295 (2020.01); G06Q 20/4014 (2013.01)] | 20 Claims |
|
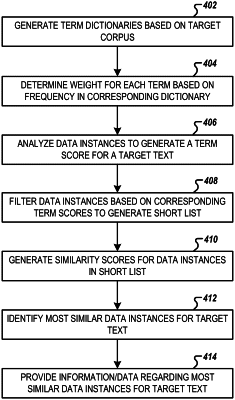
1. A method for screening data instances based on a target text of a target corpus, the method comprising:
identifying, by a processor of a screening device, a plurality of data instances for each target text of a target corpus;
for each data instance of the plurality of data instances, determining, by the screening device, a word score and an n-gram score for the data instance based on at least two term dictionaries associated with the target corpus;
filtering, by the screening device, the plurality of data instances based on the word score and the n-gram score corresponding to each data instance and at least one or more of a threshold word score or a threshold n-gram score, to generate a short list of data instances;
determining, by the screening device, term similarity scores for each data instance of the short list based on a term overlap function between a term present in at least a portion of the data instance and the term present in the target text, the term being a respective word or n-gram; and
providing, by the screening device, at least one data instance of the short list and an indication of its corresponding term similarity score.
|