| CPC G06F 16/3329 (2019.01) [G06F 16/3344 (2019.01); G06F 40/30 (2020.01)] | 20 Claims |
|
1. An edge computing unit provided at a site, wherein the edge computing unit comprises a containerized system having:
at least one processor unit;
at least one server rack; and
at least one power unit;
wherein the at least one server rack comprises at least one data store programmed with:
one or more sets of instructions;
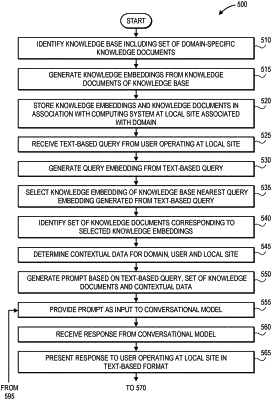
code for executing a first model, wherein the first model is configured to generate an embedding representing a descriptor of a document;
code for executing a second model, wherein the second model is configured to generate a response to a query in reply to a prompt comprising information regarding the query;
a first plurality of documents; and
a first plurality of embeddings, wherein each of the first plurality of documents comprises a question pertaining to a domain associated with the site and an answer to the question, and wherein each of the first plurality of embeddings was generated by the first model based at least in part on one of the first plurality of documents,
wherein the one or more sets of instructions, when executed by the at least one processor unit, cause the edge computing unit to at least:
receive a first set of data representing a first query from a computer system in communication with the edge computing unit, wherein the computer system comprises a headset worn by a person at the site, at least one microphone and at least one of a speaker for presenting audio data to the person or a display for presenting video data to the person;
generate a first input based at least in part on a first set of text associated with the first set of data;
provide at least the first input to the first model;
generate a first embedding by the first model in response to the first input;
identify a second plurality of embeddings, wherein each of the second plurality of embeddings is one of a predetermined number of the first plurality of embeddings similar to the first embedding;
identify a second plurality of documents, wherein each of the second plurality of documents is one of the first plurality of documents from which one of the second plurality of embeddings was generated;
generate a first prompt based at least in part on at least a portion of the first set of text and the second plurality of documents;
provide at least the first prompt as a second input to the second model;
identify a first response to the first query by the second model in response to the second input; and
transmit a second set of data representing the first response to the computer system.
|