| CPC G06F 12/0875 (2013.01) [G06F 2212/1044 (2013.01); G06F 2212/401 (2013.01)] | 17 Claims |
|
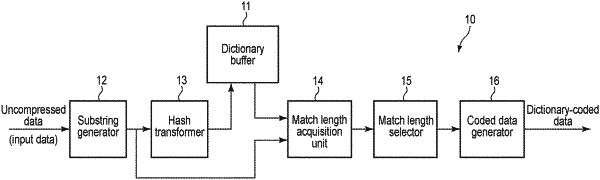
1. A dictionary compression device configured to compress uncompressed data including first input data and second input data by performing dictionary coding on the second input data subsequent to the first input data after performing dictionary coding on the first input data including a plurality of pieces of consecutive data, the dictionary compression device comprising:
a dictionary buffer including a plurality of storage areas and configured to store dictionary data in a dictionary address of a storage area of the plurality of storage areas, each of the plurality of storage areas corresponding to each of a plurality of first substrings, each of the plurality of first substrings including consecutive data, each of the plurality of first substrings including each of a plurality of pieces of data included in the first input data as a head, the dictionary data including a first substring and data before the first substring included in the first input data, the storage area corresponding to the first substring, the dictionary address corresponding to a hash value transformed from the first substrings;
a substring generator configured to generate, from the second input data, a plurality of second substrings, each of the plurality of second substrings including consecutive data, each of the plurality of second substrings including each of a plurality of pieces of data included in the second input data as a head;
a transformer configured to transform each of the second substrings into a hash value;
a read processor configured to read the dictionary data from a plurality of storage areas included in the dictionary buffer, using a hash value transformed from a third substring among the second substrings as a dictionary address;
an acquisition unit configured to compare a data string including the third substring and data before the third substring included in the second input data with the read dictionary data, and acquire at least one first match length indicating a match length between the third substring and the read dictionary data and at least one second match length indicating a match length between a fourth substring including consecutive data having data before data at a head of the third substring as a head and the read dictionary data; and
a coded data generator configured to generate coded data for the second input data based on the acquired first and second match lengths, wherein
dictionary data including the second substring and data before the second substring included in the second input data is written in a storage area corresponding to the second substring, with a hash value that is transformed from the second substring as a dictionary address.
|