| CPC G06F 11/3664 (2013.01) [G06F 11/3688 (2013.01); G06F 11/3696 (2013.01); H04L 9/3236 (2013.01)] | 20 Claims |
|
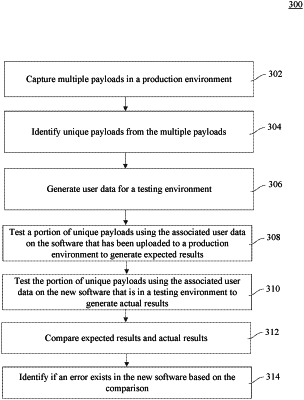
1. A method comprising:
identifying a plurality of payloads that correspond to scenarios in a production computing environment;
determining hashes for the plurality of payloads by:
identifying a subset of attributes in a plurality of attributes in each payload in the plurality of payloads, wherein the subset of attributes include data from the scenarios in the production computing environment; and
determining a hash of the identified subset of attributes in the each payload;
aggregating payloads in the plurality of payloads that have a same first hash in the hashes into a first set of payloads;
aggregating payloads in the plurality of payloads that have a same second hash in the hashes into a second set of payloads;
selecting a first payload from the first set of payloads aggregated according to the first hash and a second payload from the second set of payloads aggregated according to the second hash into a set of unique payloads, wherein the first payload includes first values of the subset of attributes and the second payload includes second values of the subset of attributes different from the first values;
creating user data, wherein the user data is associated with the set of unique payloads;
testing the set of unique payloads with the user data in a first testing environment to generate expected results, wherein the first testing environment includes software components in the production computing environment;
testing the set of unique payloads with the user data in a second testing environment to generate actual results, wherein the second testing environment includes the software components in the production computing environment and new software;
comparing the expected results with the actual results; and
identifying an error in the new software based on the comparing.
|