| CPC G06F 1/3231 (2013.01) [G06F 1/3287 (2013.01); G06F 3/16 (2013.01); G10L 13/02 (2013.01); G10L 15/08 (2013.01); G10L 2015/088 (2013.01)] | 17 Claims |
|
1. A method comprising:
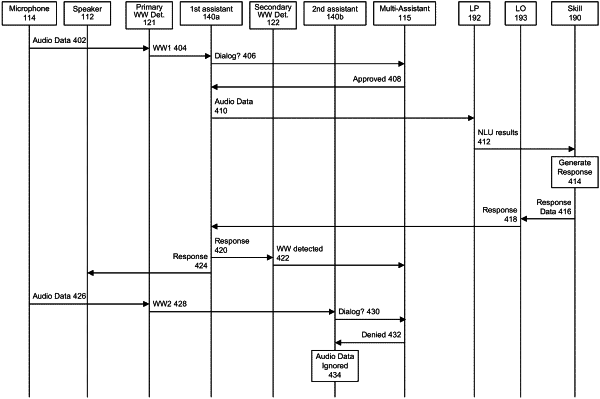
receiving, by a device, first input audio data representing first input audio detected by a microphone of the device, the device including a first component associated with a first command processing subsystem (CPS), a second component associated with a second CPS, and a third component configured to manage operations of the first component and the second component;
detecting, in the first input audio data, a representation of a first wakeword corresponding to the first CPS;
sending, to the first component a first indication that the representation of the first wakeword was detected;
in response to the first indication, sending, to the third component, first data to comprising a first request for authorization to use the first component to initiate a first dialog session between the device and the first CPS;
receiving, by the first component and from the third component, a first response indicating that the first request has been granted;
based on the first response, causing the first CPS to perform speech processing on at least a portion of the first input audio data;
receiving CPS response data from the first CPS;
outputting, by a speaker of the device, first output audio based on the CPS response data;
receiving, by the device, second input audio data representing second input audio detected by the microphone;
detecting, in the second input audio data, a first representation of a second wakeword;
sending, to the second component, a second indication that the first representation of the second wakeword was detected;
in response to the second indication, sending, to the third component, second data comprising a second request for authorization to use the second component to initiate a second dialog session with the second CPS;
determining that the first representation of the second wakeword was detected during an interval of time in which the first output audio was being output;
receiving, by the second component and from the third component, a second response indicating that the second request has been denied, wherein denying the second request is based at least in part on the first representation of the second wakeword having been detected during the interval; and
based on the second response, refraining from causing the second CPS to perform speech processing on at least a portion of the second input audio data.
|