| CPC G05D 1/0088 (2013.01) [G06F 9/4881 (2013.01); G06F 9/522 (2013.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/063 (2013.01); G06N 3/084 (2013.01); G06F 9/46 (2013.01); G06T 1/20 (2013.01)] | 20 Claims |
|
1. A processing apparatus comprising:
a first processing resource;
a second processing resource coupled with the first processing resource, wherein the first processing resource and the second processing resource each include a separate respective local memory and instruction execution resources configured to concurrently execute a plurality of threads of a thread group;
a shared memory coupled with the first processing resource and the second processing resource, wherein the shared memory is accessible to the first processing resource and the second processing resource; and
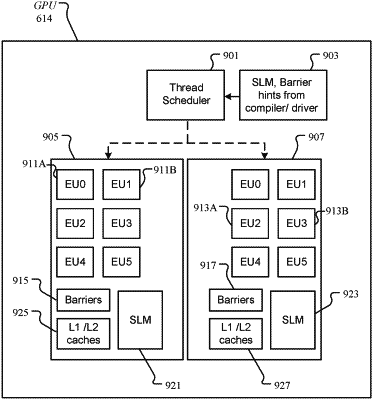
scheduler hardware including first circuitry configured to:
receive the thread group for scheduling, wherein the thread group includes program code configured to store data within the local memory and is programmed for execution on a single processing resource;
based on a hint associated with the thread group, map the local memory to the shared memory;
schedule threads of the thread group for execution via multiple processing resources including the first processing resource and the second processing resource, wherein the program code of the thread group that is configured to store data within the local memory is to store the data within the shared memory;
second circuitry to:
determine that the thread group is associated with a hint;
evaluate a memory access performance impact of mapping the local memory to the shared memory based on an amount of shared memory to be accessed by the program code of the thread group due to the mapping; and
based on the evaluation, provide the hint to the first circuitry; and
wherein the first processing resource and the second processing resource are to execute scheduled threads of the thread group via respective instruction execution resources.
|