| CPC G10L 25/30 (2013.01) [G06F 18/217 (2023.01); G06N 3/084 (2013.01); G06N 3/088 (2013.01); G06N 5/046 (2013.01); G10L 25/48 (2013.01)] | 20 Claims |
|
1. A method comprising:
obtaining, by a computing system, audio data having a speech portion;
training, by the computing system, a neural network to learn a non-semantic speech representation based on the speech portion of the audio data;
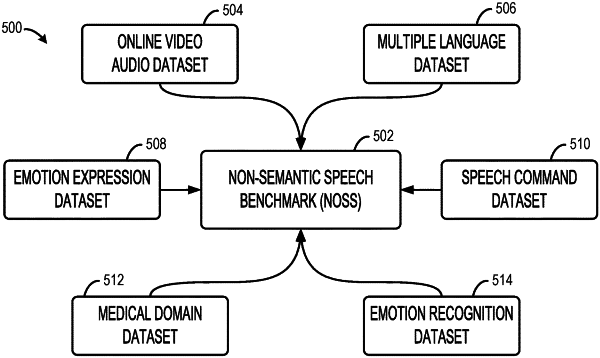
evaluating performance of the non-semantic speech representation based on a set of benchmark tasks corresponding to a speech domain;
performing, using a set of downstream tasks, a comparison between the non-semantic speech representation and one or more existing feature-based and learned representations to determine where the non-semantic speech representation requires improvement through a fine-tuning process;
performing, by the computing system, the fine-tuning process on the non-semantic speech representation to improve performance of the non-semantic speech on one or more downstream tasks;
generating, by the computing system, a model based on the non-semantic speech representation; and
providing, by the computing system, the model to a mobile computing device, wherein the model is configured to operate and train locally on the mobile computing device using vocal inputs having non-semantic speech from a user such that the model enables the mobile computing device to perform operations differently based on a speaker identification, a medical condition identification, or an emotion of the user.
|