| CPC G10L 15/26 (2013.01) [G06F 16/632 (2019.01); G10L 15/04 (2013.01); G10L 15/19 (2013.01); G10L 15/197 (2013.01); G10L 2015/085 (2013.01); G10L 15/183 (2013.01); G10L 15/22 (2013.01)] | 20 Claims |
|
1. A method comprising:
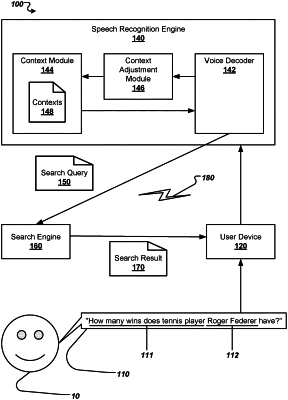
receiving, at an automated speech recognition (ASR) system implemented on a user device, voice input spoken by a user of the user device to perform an action;
determining, by the ASR system, a particular context associated with the voice input, the particular context comprising a list of named-entities corresponding to the particular context, the list of named-entities stored on a server in communication with the user device; and
processing, by the ASR system, using a language model comprising probability values associated with words or sequences of words, the voice input to generate a transcription for the voice input, the language model biasing the transcription for the voice input to include one of the named-entities in the list of named-entities stored on the server that correspond to the particular context.
|