| CPC G10L 15/16 (2013.01) [G06N 3/044 (2023.01); G06N 3/045 (2023.01)] | 20 Claims |
|
1. A method of training a neural network, the method comprising:
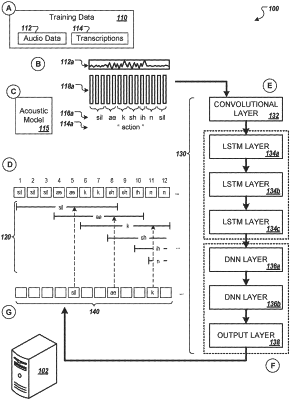
receiving, at data processing hardware, training data comprising training audio data for an utterance and a sequence of phone labels identifying respective phones that occur in the utterance;
generating, by the data processing hardware, using an acoustic model, a reference alignment indicating ground truth audio frames that the phone labels in the sequence of phone labels occur in a sequence of audio frames representing the training audio data;
for each phone label, setting, by the data processing hardware, a respective constrained range of audio frames in the sequence of audio frames that ends a predetermined number of audio frames after a respective ground truth ending audio frame that the respective phone label last occurs in the reference alignment;
providing, by the data processing hardware, the training audio data to the neural network executing on the data processing hardware, the neural network configured to:
receive, as input, each audio frame in the sequence of audio frames representing the training audio data; and
generate, as output, a sequence of output labels indicating the occurrence of each respective phone;
determining, by the data processing hardware, for each particular output label of the sequence of output labels, a corresponding delay between output of the particular output label and a corresponding respective constrained range of audio frames; and
updating, by the data processing hardware, using the sequence of output labels generated and the corresponding delays, parameters of the neural network by applying a penalty when a corresponding delay satisfies a threshold constraint.
|