| CPC G10L 15/05 (2013.01) [G06F 3/167 (2013.01); G10L 15/04 (2013.01); G10L 15/1815 (2013.01); G10L 15/22 (2013.01); G10L 15/26 (2013.01); G10L 25/78 (2013.01); G10L 2015/088 (2013.01); G10L 2025/783 (2013.01)] | 16 Claims |
|
1. A computer-implemented method that when executed on data processing hardware cause the data processing hardware to perform operations comprising:
receiving audio data of an utterance spoken by a user, the audio data captured by a client device;
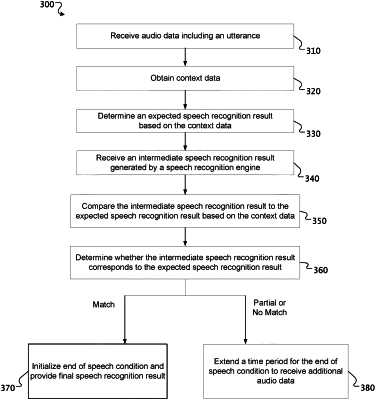
generating, using an automated speech recognizer (ASR), a first intermediate speech recognition result by performing speech recognition on the audio data of the utterance, the ASR configured to endpoint utterances by terminating performance of speech recognition on received audio data based on detecting non-speech for at least an end of speech (EOS) timeout duration;
while receiving the audio data of the utterance and before detecting non-speech for at least the EOS timeout duration:
determining, using the ASR, a confidence level associated with the first intermediate recognition result generated by the ASR, the confidence level corresponding to a confidence of an accuracy of the first intermediate recognition result;
determining an expected speech recognition result based on context data of the client device;
based on the confidence level associated with the first intermediate speech recognition result generated by the ASR, determining that the first intermediate speech recognition result partially matches the expected speech recognition result; and
extending the EOS timeout duration by a predetermined amount of time based on determining that the first intermediate speech recognition result partially matches the expected speech recognition result;
receiving additional audio data of the utterance spoken by the user;
generating, using the ASR, a second intermediate speech recognition result by performing speech recognition on the additional audio data of the utterance spoken by the user; and
while receiving the additional audio data and before detecting non-speech for at least the extended EOS timeout duration:
determining that the second intermediate speech recognition result matches the expected speech recognition result; and
based on determining that the second intermediate speech recognition result matches the expected speech recognition result:
terminating performance of any speech recognition subsequent to generating the second intermediate speech recognition result by truncating any additional audio data received after generating the second intermediate speech recognition result; and
deactivating a microphone of the client device.
|