| CPC G06T 1/20 (2013.01) [G06F 9/5011 (2013.01); Y02D 10/00 (2018.01)] | 20 Claims |
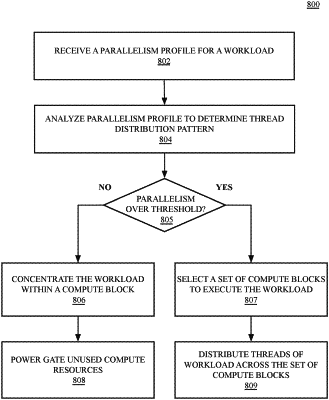
|
1. A general-purpose graphics processing unit comprising:
a processing array including multiple compute blocks, each compute block including multiple graphics compute units; and
thread dispatch circuitry configured to dispatch threads of a two-dimensional (2D) thread group based on data access locality associated with the threads, the threads of the 2D thread group associated with memory addresses within a region of memory that includes a first 2D tile of memory and a second 2D tile of memory, the thread dispatch circuitry configured to:
dispatch a first 2D sub-group of the 2D thread group to a compute block of the multiple compute blocks, the first 2D sub-group associated with the first 2D tile of memory, wherein the first 2D tile of memory is associated with a first region of a render target; and
dispatch a second 2D sub-group of the 2D thread group to the compute block of the multiple compute blocks, the second 2D sub-group associated with the second 2D tile of memory, wherein the second 2D tile of memory is associated with a second region of the render target.
|