| CPC G06N 3/08 (2013.01) [B60W 40/09 (2013.01); B60W 50/14 (2013.01); G06N 7/01 (2023.01); G06N 20/20 (2019.01); B60W 2420/403 (2013.01); B60W 2420/54 (2013.01); B60W 2540/223 (2020.02); B60W 2540/225 (2020.02); B60W 2540/229 (2020.02)] | 20 Claims |
|
1. A vehicle device comprising:
a computer readable storage medium having program instructions embodied therewith; and
one or more processors configured to execute the program instructions to cause the vehicle device to:
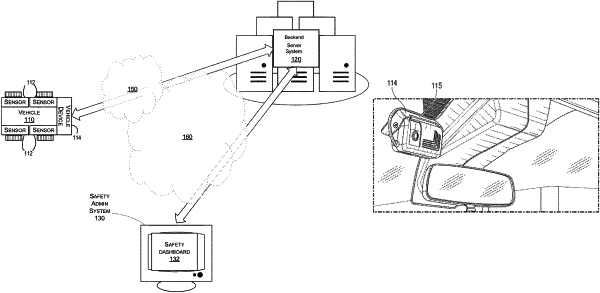
access sensor data from one or more sensors associated with a vehicle, the sensor data associated with an image of a scene;
execute an ensemble neural network configured to detect occurrence of an event associated with the vehicle, wherein the event indicates a distracted state of a driver of the vehicle, the ensemble neural network comprising a plurality of models including:
a first model configured to detect one or more hand actions of a user of the vehicle based at least in part on a hand of the user identified using the sensor data,
a second model configured to detect a head pose of the user based at least in part on a face of the user identified using the sensor data,
a third model configured to detect a gaze of the user based at least in part on the face of the user, and
a fourth model configured to predict, based at least in part on the one or more hand actions, the head pose, and the gaze, a probability of the event; and
based at least in part on the probability of the event, trigger an event alert indicative of occurrence of the event.
|