| CPC G06N 20/00 (2019.01) [G06F 16/182 (2019.01); G06Q 20/0855 (2013.01)] | 18 Claims |
|
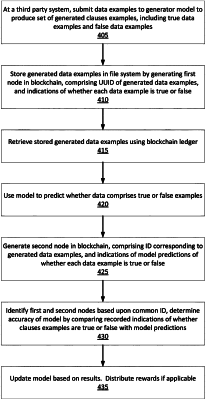
1. A computer implemented method, comprising:
receiving, a set of data examples, wherein each of the data examples is associated with an indication of whether the data example is a true data example or a false data example;
storing the set of data examples on a file system of a distributed database;
providing, by processor circuitry comprising a memory cache, data to generate, on a distributed ledger, one or more first nodes comprising at least:
an identifier corresponding to the set of data examples stored on the file system, and
for each data example of the set of data examples, the indication of whether the data example is a true data example or a false data example;
evaluating, by the processor circuitry, the set of data examples using a machine-trained model configured to, for each data example of the set of data examples, generate a prediction of whether the data example is a true data example or a false data example;
providing, by the processor circuitry, data to generate, on the distributed ledger, one or more second nodes comprising at least:
an identifier corresponding to the set of data examples stored on the file system, and
for each data example of the set of data examples, an indication of the prediction generated by the machine-trained model of whether the data example is a true data example or a false data example;
identifying, by the processor circuitry, the one or more first nodes and one or more second nodes from the distributed ledger, based upon a common identifier corresponding to the set of data examples;
performing, by the processor circuitry, a comparison between the indications of the one or more first nodes of whether each data example is a true data example or a false data example and the indications of the one or more second nodes of predictions generated by the machine-trained model, the comparison being indicative of an accuracy of predictions generated by the machine-trained model;
determining, by the processor circuitry, based upon results of the comparison, a number of correct predictions generated by the machine-trained model and a number of incorrect predictions generated by the machine-trained model;
determining, by the processor circuitry, a score for the machine-trained model based upon a weighted difference between the number of correct predictions and the number of incorrect predictions; and
updating, by the processor circuitry, the machine-trained model based upon results of the comparison.
|