| CPC G06F 40/279 (2020.01) [G06N 3/08 (2013.01); G06N 20/10 (2019.01); G06V 30/41 (2022.01); G06V 30/19 (2022.01)] | 20 Claims |
|
1. A computer-implemented method for rapid language detection of documents, comprising:
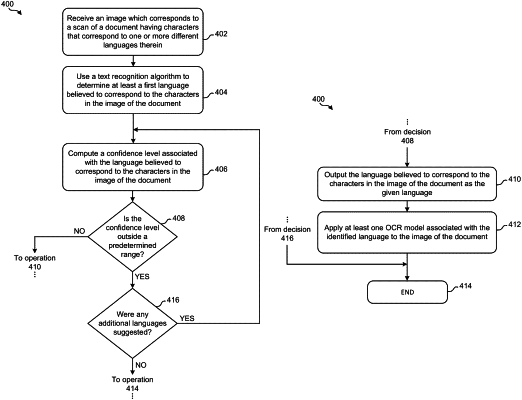
receiving an image of a document having characters that correspond to a given language;
using a text recognition algorithm to determine a first language believed to correspond to the characters in the image of the document by:
using a generated mixed language corpus to convert an input sequence of the characters in the image of the document into one or more n-gram sequences, and
computing a hidden layer vector for the one or more n-gram sequences,
wherein the text recognition algorithm is trained using a simple shallow neural network and the generated mixed language corpus,
wherein the generated mixed language corpus is formed by:
randomly sampling one or more libraries having vocabulary and/or characters therein, and
combining the randomly sampled vocabulary and/or characters from the one or more libraries to form the generated mixed language corpus;
computing a first confidence level associated with the first language believed to correspond to the characters in the image of the document;
determining whether the first confidence level associated with the first language is outside a predetermined range; and
in response to determining that the first confidence level associated with the first language is not outside the predetermined range, outputting the first language as the given language.
|