| CPC G06F 3/167 (2013.01) [G06F 3/0482 (2013.01); G06F 3/04847 (2013.01); G06F 3/04883 (2013.01); G10L 15/22 (2013.01); G10L 2015/223 (2013.01)] | 19 Claims |
|
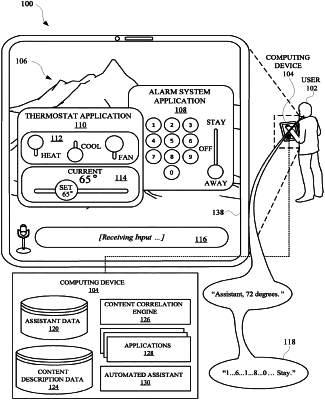
1. A method implemented by one or more processors, the method comprising:
determining that a user has provided a spoken utterance to an automated assistant accessible via a computing device,
wherein the spoken utterance includes one or more terms for performing an action, wherein the one or more terms in the spoken utterance do not include any term explicitly identifying the action to be performed;
comparing the one or more terms in the spoken utterance to content description data provided by one or more applications accessible via the computing device,
wherein the content description data characterizes one or more GUI elements of the one or more applications,
wherein the one or more GUI elements, when displayed via a display of the computing device, are capable of being interacted with by the user, and
wherein the content description data is not displayed to the user via the display;
determining, based on comparing the one or more terms in the spoken utterance to the content description data that characterizes the one or more GUI elements the one or more applications, that the spoken utterance is directed to a first application, of the one or more applications; and
in response to determining that the spoken utterance is directed to the first application:
generating application input data for the first application to perform the action; and
providing the application input data to the first application, wherein providing the application input data to the first application causes the action to be performed by the first application.
|