| CPC B25J 9/163 (2013.01) | 20 Claims |
|
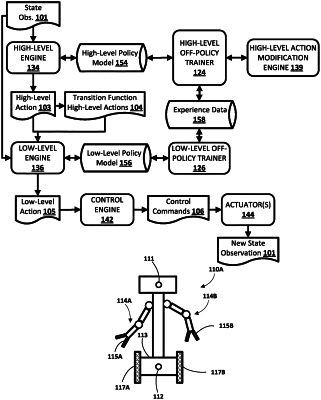
1. A method of off-policy training of a higher-level policy model of a hierarchical reinforcement learning model for use in robotic control, the method implemented by one or more processors and comprising:
retrieving, from previously stored experience data, for a robot, generated based on controlling the robot during a previous experience episode using the hierarchical reinforcement learning model in a previously trained state:
a stored state based on an observed state of the robot in the previous experience episode;
a stored higher-level action for transitioning from the stored state to a goal state;
wherein the stored higher-level action was previously generated, during the previous experience episode, using the higher-level policy model, and
wherein the stored higher-level action was previously processed, during the previous episode using a lower-level policy model of the hierarchical reinforcement learning model, in generating a lower-level action applied to the robot during the previous experience episode; and
at least one stored environment reward determined based on application of the lower-level action during the previous episode;
determining a modified higher-level action to utilize in lieu of the stored higher-level action for further training of the hierarchical reinforcement learning model, wherein determining the modified higher-level action is based on a currently trained state of the lower-level policy model, the currently trained state of the lower-level policy model differing from the previously trained state; and
further off-policy training the higher-level policy model using the stored state, using the at least one stored environment reward, and using the modified higher-level action in lieu of the stored higher-level action.
|