| CPC H04N 19/105 (2014.11) [H04N 19/132 (2014.11); H04N 19/159 (2014.11); H04N 19/176 (2014.11); H04N 19/184 (2014.11); H04N 19/46 (2014.11); H04N 19/583 (2014.11); H04N 19/625 (2014.11); H04N 19/64 (2014.11)] | 18 Claims |
|
1. A method for video encoding, comprising:
dividing a current picture into a plurality of separate template slices, each template slice comprising a plurality of blocks;
signaling at least one of a number of template slices in said current picture and a position of each template slice in said current picture at a sequence level or a picture level;
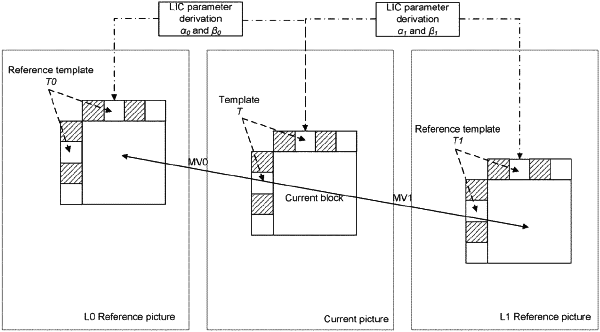
determining an inter prediction mode for a block in a current template slice, wherein the inter prediction mode is selected from among at least one template-based inter prediction mode and at least one non-template-based inter prediction mode; and
generating a prediction for each block in the current template slice, wherein the prediction of a block in the current template slice using a template-based inter prediction mode is based on samples in a template region for the block and is constrained from using for the prediction any samples that are in the current picture but are outside the current template slice, wherein non-template-based inter prediction modes are allowed to use, for the prediction, samples that are outside the current template slice, and wherein the template region includes previously reconstructed neighboring samples, in the current template slice, for the block.
|