| CPC H04N 13/271 (2018.05) [G06T 7/579 (2017.01); G06T 7/593 (2017.01); G06T 7/73 (2017.01); G06T 2207/10016 (2013.01); G06T 2207/10028 (2013.01); G06T 2207/20081 (2013.01); H04N 2013/0081 (2013.01); H04N 2013/0088 (2013.01)] | 20 Claims |
|
12. A computer-implemented method comprising:
receiving an image of a scene;
inputting the image into a depth-pose hybrid model, the depth-pose hybrid model trained with a process including:
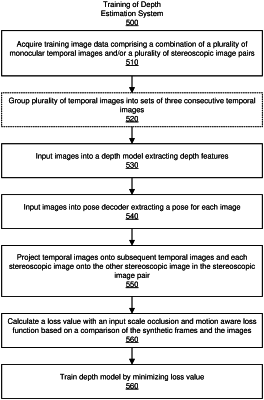
acquiring a set of images;
inputting the set of images into the depth-pose hybrid model to extract depth maps and poses for the set of images based on parameters of the depth-pose hybrid model;
generating synthetic frames based on the depth maps and the poses for the set of images;
calculating a loss value with an input-scale occlusion-aware and motion-aware loss function based on a comparison of the synthetic frames and the set of images; and
adjusting the parameters of the depth-pose hybrid model based on the comparison of the synthetic frames and the set of images; and
generating, by the depth-pose hybrid model, a depth map of the scene corresponding to the image of the scene.
|