| CPC G16B 30/00 (2019.02) [G06F 16/13 (2019.01); G06F 16/1744 (2019.01); G16B 15/00 (2019.02); G16B 50/50 (2019.02)] | 8 Claims |
|
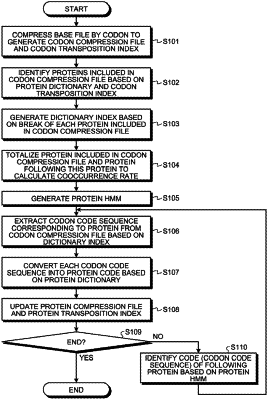
1. A method of identification comprising:
acquiring a protein file in which a plurality of proteins including a plurality of amino acids are arranged, using a processor;
first identifying a plurality of primary structure candidates with any position included in the protein file as a starting position, and identifying an end of each of the primary structure candidates based on a primary structure dictionary index that indicates a position of a primary structure included in the protein file, using the processor;
second identifying one primary structure among the primary structure candidates based on a combination of a primary structure and each amino acid and a primary structure table, where each amino acid is positioned at the identified end of each of the primary structure and the primary structure table associates a primary structure and a cooccurrence rate of a certain amino acid combination positioned at an end of the primary structure, wherein the second identified primary structure has the highest co-occurrence rate among the primary structure candidates, using the processor;
generating a primary structure compression file by compressing the protein file in units of primary structures based on the primary structure identified by the second identifying that is repeatedly performed and a primary structure dictionary associating a primary structure and a code with each other, the generated primary structure compression file including information in which a plurality of primary structure codes are arranged, using the processor; and
generating a primary structure transposition index associating a primary structure type and a corresponding offset position in a sequence in the primary structure compression file with each other, using the processor.
|