| CPC G10L 19/038 (2013.01) [G06N 3/045 (2023.01); G06N 3/08 (2013.01); G10L 25/30 (2013.01); G10L 2019/0002 (2013.01)] | 22 Claims |
|
1. A method performed by one or more computers, the method comprising:
receiving a compressed representation of an audio waveform;
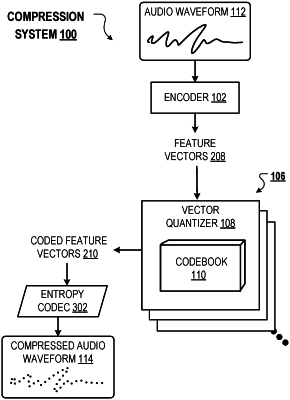
decompressing the compressed representation of the audio waveform to obtain a respective coded representation of each of a plurality of feature vectors representing the audio waveform,
wherein the coded representation of each feature vector identifies a plurality of code vectors, including a respective code vector from a respective codebook of each vector quantizer in a sequence of vector quantizers, that define a quantized representation of the feature vector, and
wherein for each of the plurality of feature vectors, the sequence of vector quantizers has generated the coded representation of the feature vector by performing operations comprising:
for a first vector quantizer in the sequence of vector quantizers:
receiving the feature vector;
identifying, based on the feature vector, a respective code vector from the codebook of the vector quantizer to represent the feature vector; and
determining a current residual vector based on an error between: (i) the feature vector, and (ii) the code vector that represents the feature vector;
wherein the coded representation of the feature vector identifies the code vector that represents the feature vector;
generating a respective quantized representation of each feature vector from the coded representation of the feature vector; and
processing the quantized representations of the feature vectors using a decoder neural network to generate an output audio waveform.
|