| CPC G10L 15/26 (2013.01) [G10L 15/32 (2013.01); H04M 1/02 (2013.01); H04M 1/663 (2013.01); H04M 3/4286 (2013.01); H04M 3/5191 (2013.01)] | 18 Claims |
|
1. A method implemented by one or more processors, the method comprising:
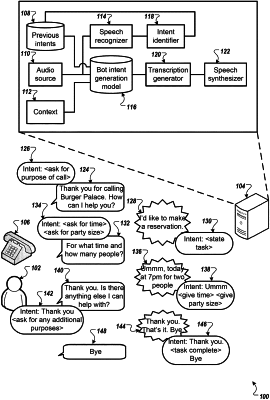
receiving audio data of an utterance spoken by a user during a portion of an ongoing conversation between the user and a bot, the audio data being captured by one or more microphones of a computing device of the user;
determining, based on processing the audio data of the utterance spoken by the user during the portion of the ongoing conversation between the user and the bot, a representation of the utterance received during the portion of the ongoing conversation;
determining a context of the ongoing conversation between the user and the bot, the context of the ongoing conversation between the user and the bot being based on one or more previous portions of the ongoing conversation between the user and the bot, and the one or more previous portions of the ongoing conversation between the user and the bot occurring prior to receiving the utterance spoken by the user during the portion of the ongoing conversation between the user and the bot;
determining a corresponding user intent for one or more of the previous portions of the ongoing conversation between the user and the bot;
causing, based on processing at the least (i) the representation of the utterance received during the ongoing conversation, (ii) the context of the ongoing conversation, and (iii) the corresponding user intent for one or more of the previous portions of the ongoing conversation, a reply by the bot, to the utterance, to be generated; and
causing synthesized speech, that captures the reply by the bot to the utterance, to be provided for audible presentation to the user, the synthesized speech being provided for audible presentation to the user via one or more speakers of a computing device of the user.
|