| CPC G10L 15/00 (2013.01) [G10L 15/22 (2013.01); G10L 15/07 (2013.01); G10L 2015/221 (2013.01); G10L 15/26 (2013.01)] | 16 Claims |
|
1. A method comprising:
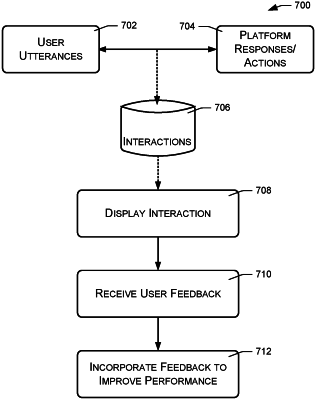
receiving, via one or more processors of a device, first input data associated with a first utterance of a user instructing the device to perform an action;
receiving, via the one or more processors of the device, output data to be output via an output component, the output data requesting feedback from the user based at least in part on the user instructing the device to perform the action;
receiving, via the one or more processors and at least partially in response to the output data, second input data associated with a second utterance of the user providing the feedback;
causing presentation of text on a display representing the second utterance of the user providing the feedback;
receiving, via an input component presented on the display along with the text, third input data representing an indication that the text presented on the display accurately represents the second utterance of the user providing the feedback;
based at least in part on the third input data, causing the second input data to update a model for speech processing;
receiving, via the one or more processors of the device, fourth input data corresponding to a third utterance of the user;
causing the fourth input data to undergo speech processing using the model as updated; and
receiving, based at least in part on the fourth input data and the model as updated, a response to the fourth input data.
|