| CPC G08G 3/02 (2013.01) [G05D 1/0088 (2013.01); G05D 1/0206 (2013.01); G06N 3/08 (2013.01)] | 6 Claims |
|
1. A collision avoidance method for a swarm of unmanned surface vehicles based on deep reinforcement learning, comprising:
S1: establishing a vehicle coordinate system, and designing an unmanned surface vehicle (USV) motion model based on the vehicle coordinate system, wherein the USV motion model is used to reflect a motion state of a USV;
S2: based on the USV motion model, expressing environmental features in the vehicle coordinate system as environmental observation values of a fixed dimension, and designing a reward and punishment function of collision avoidance effect based on the environmental observation values, wherein the reward and punishment function of collision avoidance effect is used to judge a perfection degree of a collision avoidance decision of the USV;
wherein based on the USV motion model, the expressing environmental features in the vehicle coordinate system as environmental observation values of a fixed dimension comprises:
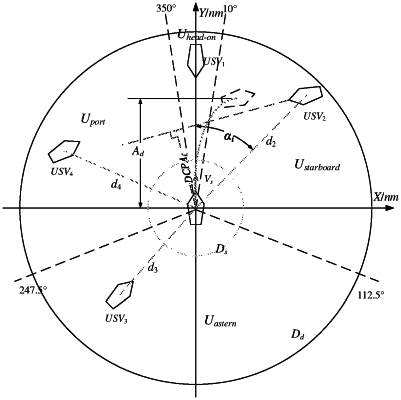
according to international regulations for preventing collisions at sea (COLREGS), dividing n number of fields based on a vehicle-side angle of a USVj as an obstacle, and obtaining a USV environmental observation value of each of the n number of fields, wherein the USV environmental observation value of each of the n number of fields comprises the vehicle-side angle, swarm movement characteristics, movement trends and danger degrees;
combining the USV environmental observation value in each of the n number of fields to form a four-dimensional matrix, and adding weights to the four-dimensional matrix corresponding to each of the n number of fields to obtain a final USV environmental observation value;
wherein the USV environmental observation value in each of the n number of fields is obtained through
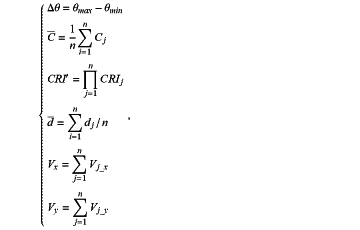 where θmax and θmin respectively represent a maximum vehicle-side angle and a minimum vehicle-side angle of the obstacle in each of the n fields; Cj represents a movement direction of the USVj as the obstacle; CRIj represents a danger degree of the USVj; dj represents a distance between a USVj and the USVj as the obstacle, Vjx and Vjy respectively represent a x horizontal component and a y vertical component of a velocity of the USVj as the obstacle;
wherein the four-dimensional matrix of each of the n fields is formed by Su=[Δθ C CRI′ d Vx Vy], where u=(1, 2, . . . , n), and the final USV environmental observation value is formed by st=[Vi Ci χ1S1 χ2S2 χ3S3 . . . χnSn]T, where χ1, χ2, χ3, . . . , χn are the weights corresponding to the n fields respectively;
wherein the reward and punishment function is designed by
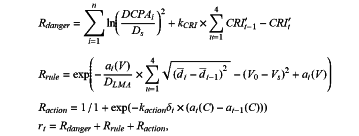 where CRIt′ represents a danger degree of field at time t, dt represents an average distance of the obstacle of field at time t, at(C) represents a course change in a decision set, at(V) represents a velocity change of the decision set, Rdanger represents a changing trend of the danger degree considering reward and punishment calculations of encounter situation, Rrule represents a deviation between a current decision and the COLREGS and the deviation is a punitive negative value when the COLREGS is violated, Raction represents a continuity of decision-making actions and calculates an impact of decision-making shock in collision avoidance, rt represents a reward and punishment value formed by combining the factors Rdanger, Rrule and Raction, DCPAi represents a minimum encounter distance between the USV and the USVi, Ds represents a safe distance between the USV and the USVi to avoid collision, kCRI represents an impact coefficient of collision risk, DLMA represents a shortest distance between the USV and the USVi to avoid collision when one USV implements full rudder rotation to avoid collision and the other USV is going straight, V0 represents an initial velocity of the USV, Vs represents a safe velocity of the USV calculated considering an influence of USV velocity, a safety distance between vehicles and a navigation environment, kaction represents a coefficient of action influence, and δt represents a rudder angle of the USV;
S3: integrating a long short-term memory (LSTM) neural network and deep reinforcement learning principles to build a collision avoidance training model for the swarm of USVs; and
S4: training the USV to avoid collision in an environment with the swarm of USVs based on the collision avoidance training model for the swarm of USVs.
|