| CPC G06V 40/28 (2022.01) [G06N 20/00 (2019.01); G06V 40/10 (2022.01); G10L 15/22 (2013.01); G10L 2015/225 (2013.01)] | 18 Claims |
|
12. A nonverbal information generation model learning apparatus comprising:
a hardware processor that:
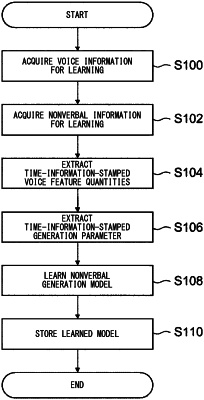
acquires voice information corresponding to voice of a speaker and time information representing times of predetermined units when the voice information is emitted;
acquires nonverbal information representing information relating to behavior of the speaker when the speaker performed speaking corresponding to the voice and time information representing times at which the behavior was performed and corresponding to the nonverbal information, and creates time-information-stamped nonverbal information;
extracts time-information-stamped voice feature quantities representing feature quantities of the voice information from the acquired voice information and the time information corresponding to the voice information; and
learns a nonverbal information generation model for generating the acquired time-information-stamped nonverbal information on the basis of the extracted time-information-stamped voice feature quantities.
|