| CPC G06V 30/153 (2022.01) [G06V 30/18181 (2022.01); G06V 30/274 (2022.01); G06V 30/41 (2022.01)] | 20 Claims |
|
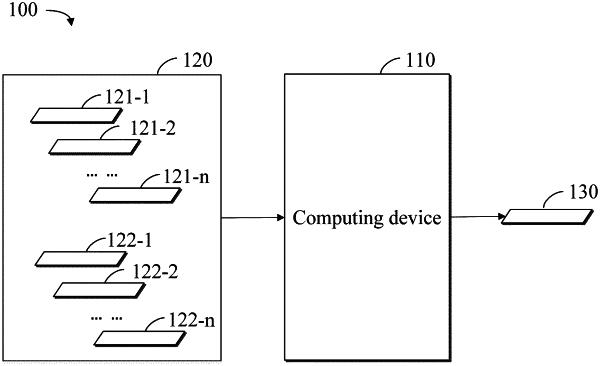
9. An electronic device, comprising:
at least one processor; and
a memory communicatively connected to the at least one processor, wherein the memory stores instructions executable by the at least one processor, and the instructions, when executed by the at least one processor, cause the at least one processor to implement operations of performing a text matching, comprising:
determining a word set and a plurality of semantic units from a text set, wherein the word set is associated with a first predetermined attribute, the plurality of semantic units are used for determining a pointwise mutual information between words in the word set, the text set contains a plurality of first texts indicating an object information and a plurality of second texts indicating an object demand information, and a matching relationship between the plurality of first texts and the plurality of second texts is pre-marked;
generating a graph based on the text set, the plurality of semantic units and the word set, wherein a weight of an edge between a text node and a word node in the graph is generated based on a term frequency-inverse document frequency of a word represented by the word node with respect to the text set and a text represented by the text node, and a weight of an edge between two word nodes in the graph is generated based on a pointwise mutual information of two words represented by the two word nodes with respect to the plurality of semantic units; and
generating a final feature representation associated with the text set and the word set based on the graph and a graph convolution model, so as to perform the text matching.
|