| CPC G06V 20/41 (2022.01) [G06F 40/279 (2020.01); G06F 40/284 (2020.01); G06V 10/26 (2022.01); G06V 10/761 (2022.01); G06V 10/774 (2022.01); G06V 10/776 (2022.01); G06V 10/806 (2022.01); G06V 20/46 (2022.01); G06V 20/47 (2022.01)] | 20 Claims |
|
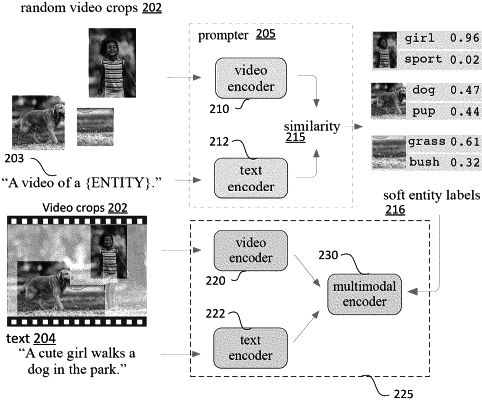
1. A method of video-and-language alignment contrastive pretraining, the method comprising:
obtaining, via a data interface, a plurality of video frames and a plurality of text descriptions corresponding to the plurality of video frames;
encoding, by a video encoder, the plurality of video frames into video feature representations;
encoding, by a text encoder, the plurality of text descriptions into text feature representations;
computing similarity scores between the video feature representations and the text feature representations;
computing a first contrastive loss based at least in part on an exponential of computed similarity scores corresponding to a matching pair of a first video frame and a first text description and one or more pairs of the first video frame and text descriptions that do not match the first video frame;
computing a second contrastive loss based at least in part on an exponential of computed similarity scores corresponding to the matching pair of the first video frame and the first text description and one or more pairs of the first text description and video frames that do not match the first text description;
computing a video-text contrastive loss by taking a weighted sum of the first and the second contrastive losses; and
updating the video encoder and the text encoder based at least in part on the video-text contrastive loss.
|