| CPC G06V 10/7753 (2022.01) [G06F 18/2155 (2023.01); G06F 18/22 (2023.01); G06V 10/82 (2022.01)] | 12 Claims |
|
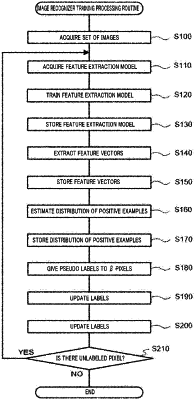
1. An image recognizer training device comprising a processor configured to execute operations, comprising:
training a feature representation model based on a set of images that include an image including pixels each labeled with a positive example label or a negative example label and an image including unlabeled pixels, the feature representation model being a model for extracting feature vectors of the pixels and trained such that an objective function is minimized, the objective function being expressed as a function that includes a value that is based on a difference between a distance between feature vectors of pixels labeled with the positive example label and a distance between a feature vector of a pixel labeled with the positive example label and a feature vector of an unlabeled pixel, and a value that is based on a difference between a distance between a feature vector of a pixel labeled with the positive example label and a feature vector of an unlabeled pixel and a distance between a feature vector of a pixel labeled with the positive example label and a feature vector of a pixel labeled with the negative example label;
extracting feature vectors of a plurality of pixels included in the images based on the feature representation model trained;
estimating a distribution of feature vectors that are extracted with respect to pixels labeled with the positive example label;
calculating, with respect to each unlabeled pixel, a likelihood that the pixel is a positive example based on the distribution estimated and give the positive example label to pixels, a number of which is a first sample number determined in advance, in descending order of the likelihood and give the negative example label to pixels, the number of which is a second sample number determined in advance, in ascending order of the likelihood; and
determining whether or not there is an unlabeled pixel among pixels of the images, and if there is an unlabeled pixel, causes repeated execution of training, extraction of feature vectors, estimation, and labeling, wherein for each unlabeled pixel, the likelihood of the unlabeled pixel being a positive example is labeled based on a normal distribution and the feature vector of the unlabeled pixel.
|