| CPC G06T 19/20 (2013.01) [G06V 10/774 (2022.01); G06V 10/82 (2022.01); G06F 3/0482 (2013.01); G06T 2210/04 (2013.01); G06T 2219/012 (2013.01); G06T 2219/2016 (2013.01)] | 43 Claims |
|
1. A non-transitory computer readable medium having instructions thereon, the instructions configured to cause a computer to execute, in a browser, an interactive three dimensional electronic representation of a physical scene at a location to determine attributes of the physical scene, the browser having a limited computing capability compared to a native application or hardware usable by the computer, the interactive three dimensional representation configured to minimize overall computing resources and processing time for determining the attributes, the instructions causing operations comprising:
receiving video images of the physical scene, the video images generated via a camera associated with a user;
generating, with a trained machine learning model, the interactive three dimensional representation of the physical scene, wherein the interactive three dimensional representation comprises a textured or untextured three-dimensional mesh with vertices connected by edges, defining triangular or quadrilateral planar faces, wherein the vertices and the faces each separately comprise position, color, and/or surface normal information;
extracting data items from the interactive three dimensional representation with the trained machine learning model, wherein the data items correspond to surfaces and/or contents in the physical scene;
determining attributes of the data items with the trained machine learning model, the attributes comprising dimensions and/or locations of the surfaces and/or contents;
identifying a subset of the data items with the trained machine learning model, the subset of the data items comprising a ceiling, a floor, and walls of the physical scene; and
causing interactive human verification of the attributes of the subset of data items by:
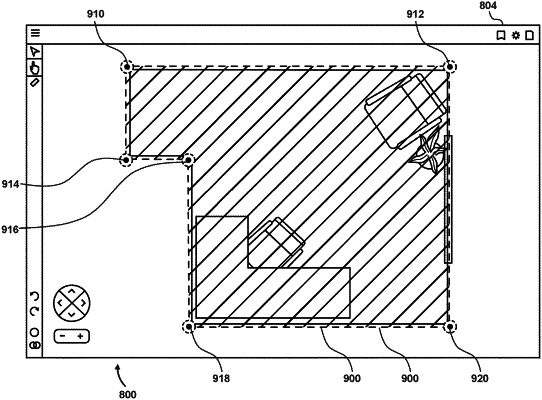
receiving user selection of the ceiling, the floor, or a wall, and flattening a view of the selected ceiling, floor, or wall from the interactive three dimensional representation to two dimensions;
receiving user adjustments to the dimensions and/or locations of the selected ceiling, floor, or wall;
receiving user indications of cut outs in the selected ceiling, floor, or wall, a cut out comprising a window, a door, or a vent in the selected ceiling, floor, or wall; and
updating, with the trained machine learning model, the interactive three dimensional representation based on adjustments to the dimensions and/or locations, and/or the indications of cut outs for continued display an manipulation in the browser;
wherein the trained machine learning model is trained by:
obtaining physical scene data associated with a specified physical scene at the location, wherein the physical scene data includes an image, a video or a prior three dimensional digital model associated with the specified physical scene; and
training the machine learning model with the physical scene data to predict a specified set of surfaces and/or contents in the specified physical scene such that a cost function that is indicative of a difference between a reference set of surfaces and/or contents and the specified set of contents is minimized.
|