| CPC G06T 15/005 (2013.01) [G06T 1/20 (2013.01); G06T 15/06 (2013.01); G06T 2210/52 (2013.01)] | 20 Claims |
|
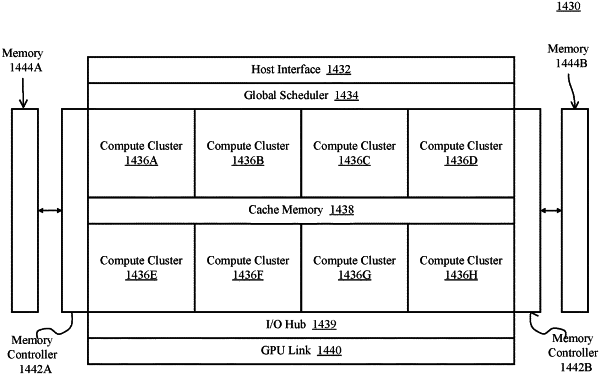
1. A method comprising:
storing program code in a plurality of cores;
executing, by a plurality of execution engines, work that is offloaded from the plurality of cores upon execution of the program code, wherein the offloaded work comprises ray tracing operations; and
storing, in a memory accessible to both of the plurality of cores and the plurality of execution engines, execution results of the offloaded work including the ray tracing operations from the plurality of execution engines, wherein the execution results of the offloaded work are provided to the plurality of cores.
|