| CPC G06Q 10/0631 (2013.01) [G06F 12/0802 (2013.01); G06F 2212/60 (2013.01); G06Q 30/0201 (2013.01)] | 20 Claims |
|
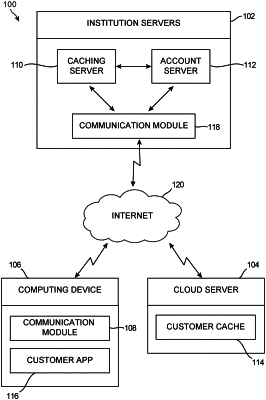
1. A system for improving the delivery of data to an a first computing device associated with a first customer of a financial institution comprising:
at least one server in the financial institution housing a machine learning module;
the machine learning module receiving customer profile data from a customer profile database, customer financial accounts data from a customer financial accounts database, and customer app history data from a customer app history database;
each of the customer profile data, the customer financial accounts data, and the customer app history data including data associated with the first customer and also including data associated with a plurality of remote customers associated with the financial institution;
wherein the machine learning module is configured to determine usage patterns among the customer profile data, the customer accounts data, and the customer app history data, and to develop rules based upon the usage patterns;
wherein the machine learning module is configured to apply the rules in order to transmit predicted data, that the machine learning module anticipates the first customer might request, to a cache when a likelihood of the predicted data being used by the first customer exceeds a confidence standard; and
the confidence standard is determined based on a first amount of computing resources needed to fulfill a request made by the first customer and based on a second amount of computing resources needed to place the predicted data into the cache.
|