| CPC G06N 3/092 (2023.01) [G06N 20/00 (2019.01); G05B 2219/32334 (2013.01); G05B 2219/33056 (2013.01); G05B 2219/34082 (2013.01); G05B 2219/40499 (2013.01); G06N 7/00 (2013.01)] | 12 Claims |
|
1. An agent device for performing exclusive reinforcement learning, the device comprising:
a processor;
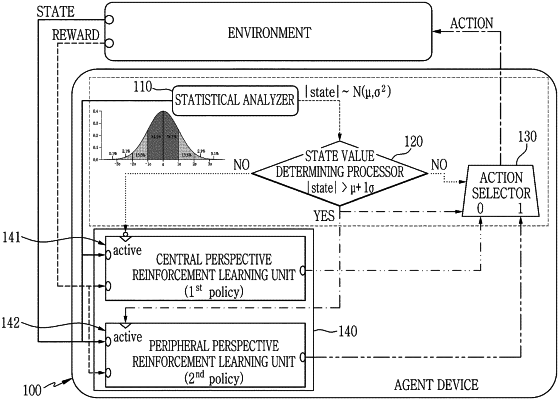
a statistical analyzer configured via the processor to collect state information of sample states of an environment and performs a statistical analysis on the sample states using the collected state information;
a state value determining processor configured to determine a first state value of a first state among the states in a training phase and a second state value of a second state among the states in an inference phase based on analysis results of the statistical analysis;
a reinforcement learning processor configured to include a plurality of reinforcement learning unit which perform reinforcement learning from different perspectives according to the first state value; and
an action selector configured via the processor to select one of actions determined by the plurality of reinforcement learning unit based on the second state value,
wherein the plurality of reinforcement learning unit includes a central perspective reinforcement learning unit and a peripheral perspective reinforcement learning unit,
the reinforcement learning processor is specifically configured to perform the reinforcement learning by using the peripheral perspective reinforcement learning unit or the central perspective reinforcement learning unit according to the first state value, and
the agent device applies the selected action to the environment and the agent device receives a reward from the environment, where the reward is input to the central perspective reinforcement learning unit and the peripheral perspective reinforcement learning unit, respectively, and
wherein:
the analysis result of the statistical analysis includes an average and a standard deviation of collected sample states,
the state value determining processor is specifically configured to determine the second state value to 1 when an absolute value of the second state is greater than a sum of the average and the standard deviation and determine the second state value to 0 when the absolute value of the second state is less than or equal to the sum of the average and the standard deviation,
the plurality of reinforcement learning unit includes a central perspective reinforcement learning unit and a peripheral perspective reinforcement learning unit, and
the action selector via the processor is specifically configured to select an action determined by the peripheral perspective reinforcement learning unit when the second state value is 1 and select an action determined by the central perspective reinforcement learning unit when the second state value is 0.
|