| CPC G06N 3/088 (2013.01) [G06N 20/00 (2019.01)] | 20 Claims |
|
1. A method comprising:
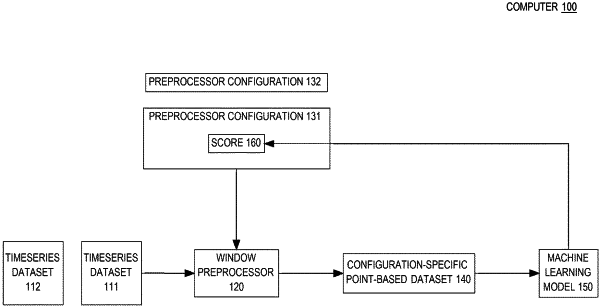
a) for each preprocessor configuration of a plurality of configurations of a window preprocessor for a training timeseries dataset for a machine learning model:
1) the window preprocessor performing based on said preprocessor configuration:
i) partitioning the training timeseries dataset into one or more sequences of windows, wherein each sequence of said one or more sequences of windows has a distinct window size;
ii) converting the training timeseries dataset into a configuration-specific point-based dataset that is based on a statistical summary operator of said preprocessor configuration, including performing for each window in each sequence of said one or more sequences of windows:
generating, for the window, a feature vector in the configuration-specific point-based dataset, and
the statistical summary operator calculating a value in the feature vector;
2) training the machine learning model based on said configuration-specific point-based dataset; and
3) calculating a score for said preprocessor configuration based on said training based on said configuration-specific point-based dataset;
b) selecting, based on said scores of the plurality of configurations of the window preprocessor, an optimal preprocessor configuration from the plurality of configurations; and
c) converting, by the window preprocessor and based on the optimal preprocessor configuration, a new timeseries dataset.
|