| CPC G06N 20/00 (2019.01) [G06F 18/2113 (2023.01); G06F 18/2163 (2023.01); G06F 18/217 (2023.01); G06N 5/025 (2013.01); G06N 5/04 (2013.01); G06N 5/046 (2013.01)] | 20 Claims |
|
1. A system, comprising:
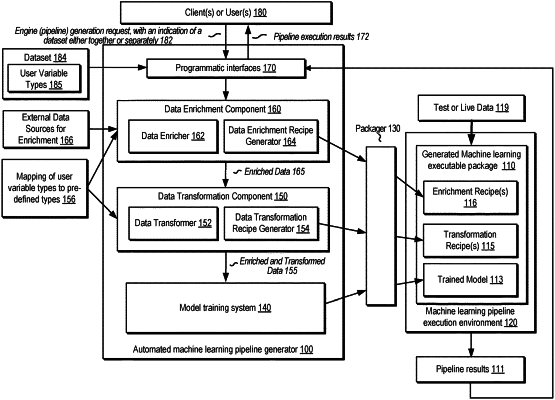
one or more computers comprising one or more processors and memory and configured to implement an automated machine learning pipeline service configured to:
provide an interface for a plurality of clients to request automated generation of machine learning engines based on datasets;
receive a request from a client via the interface to generate a machine learning engine;
receive information via the interface, wherein the information comprises an indication of a dataset, wherein the dataset comprises a plurality of data points and a plurality of user variable types, wherein individual data points comprise one or more values for a respective one or more of the user variable types such that the dataset collectively comprises a plurality of values for individual ones of the plurality of user variable types, and wherein the information further comprises an indication of a mapping of the individual ones of the user variable types to pre-defined types; and
responsive to the receipt of the request to generate the machine learning engine via the interface, the automated machine learning pipeline service is further configured to:
enrich at least some of the one or more values of at least some of the individual data points of the dataset using one or more data sources external to the dataset, to produce an enriched version of the dataset, and to produce enrichment recipes defining the process of the enrichment for the values of the individual user variable types;
transform at least some of the one or more values of at least some of the individual data points of the dataset based at least in part on the pre-defined types of the respective individual ones of the user variable types, to produce a transformed version of the enriched dataset, and to produce transformation recipes defining the process of the transformation for the values of the individual user variable types;
train a machine learning model using at least some of the data points of the enriched and transformed dataset; and
compose an executable package comprising an enrichment component based at least in part on the enrichment recipes, a transformation component based at least in part on the transformation recipes, and the trained machine learning model, wherein the executable package is configured to generate scores for at least other data points external to the dataset.
|