| CPC G06F 9/4881 (2013.01) [G06F 9/3836 (2013.01); G06F 9/5027 (2013.01); G06F 12/02 (2013.01); G06N 3/063 (2013.01)] | 20 Claims |
|
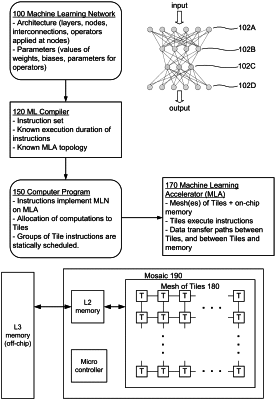
1. A method for implementing a machine learning network (MLN) by executing a computer program of instructions on a machine learning accelerator (MLA), the MLA comprising a plurality of Tiles and an on-chip memory implemented on a semiconductor die, wherein Tiles in the plurality of Tiles are configured to execute Tile instructions that access data stored in the on-chip memory, and wherein the Tiles are organized into one or more meshes of interconnected Tiles, the method comprising:
executing a non-deterministic phase of instructions that transfer data from an off-chip memory to addresses in the on-chip memory by:
determining whether the addresses in the on-chip memory are storing live data for future use by the Tiles; and
responsive to determining that the addresses are not storing any live data for future use, transferring the data from the off-chip memory to the addresses in the on-chip memory and marking the addresses as storing live data; and
the Tiles executing a deterministic phase of statically scheduled Tile instructions that implement computations from the MLN; wherein an order and static schedule for the execution by the Tiles of the statically scheduled Tile instructions is determined by a compiler before run-time and does not depend on run-time conditions, branching or values of inputs to the instructions, and the statically scheduled Tile instructions access the live data that was stored in the on-chip memory during the non-deterministic phase.
|