| CPC G06F 9/4843 (2013.01) [G06F 9/3009 (2013.01); G06F 9/522 (2013.01); G06T 1/20 (2013.01); G06F 8/458 (2013.01); G06F 9/30087 (2013.01)] | 20 Claims |
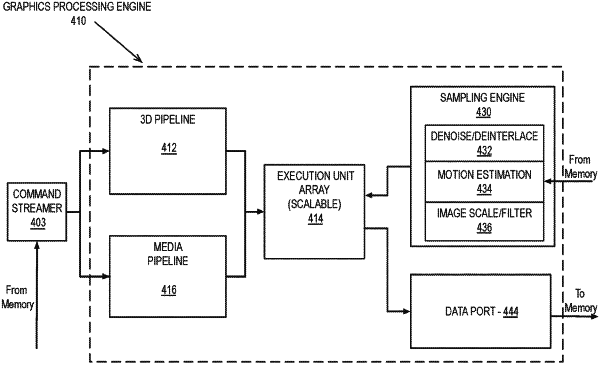
|
1. An apparatus comprising:
one or more processors to:
receive a barrier message associated with a barrier synchronization request, the barrier message including one or more source operands and an identifier of a specified operation; and
perform an operation including a merged write-barrier-read operation in response to the barrier synchronization request from a set of threads in a work group and synchronize the set of threads, wherein the merged write-barrier-read operation is performed to enable accelerated reduction operations associated with a set of map operations to write local data for global calculation, and the merged write-barrier-read operation is further performed to facilitate completion of atomic operations and ready the global calculations to determine one or more convergence conditions.
|