| CPC G06F 40/30 (2020.01) [G06F 17/18 (2013.01)] | 6 Claims |
|
1. A computerized system for conducting human-machine conversations, comprising:
a computer comprising a processor connected to memory storing computer-implemented language processing software comprising:
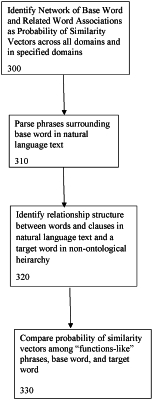
a network of associations comprising base words and related words, wherein the network of associations comprises respective data structures that associate the base words and the related words according to domains of words, wherein the respective data structures store parent-child relationship definitions, functions-like relationship definitions, and statistical measures of relationships between the base words and the related words;
a user interface connected to the computer and configured to receive natural language inputs and to provide responses from the computer using the language processing software, wherein the language processing software implements a method comprising the steps of:
identifying at least one base word in a respective natural language input;
identifying at least one of the related words in the network as at least one target word relative to the base word from the natural language input;
using the parent-child relationship definitions in the network of associations, identifying relationship structures between the at least one target word and the at least one base term;
identifying respective functions-like phrases associated with the at least one base term in the natural language input and comparing the respective functions-like phrases with the functions-like relationship definitions in the network of associations;
using the parent-child relationship definitions and the functions-like relationship definitions to calculate the statistical measures of relationships between the at least one base term and respective target words in the network of associations;
weighting the statistical measures of relationships;
identifying a probability that a respective domain of words exhibits shared features between the base word and the respective target words to an extent that the base word is a prototype within the domain of words; and
computing a response with terms from the respective domain of words.
|